Posts tagged dask
TPC-H Benchmarks for Query Optimization with Dask Expressions
- 05 October 2023
Dask-expr is an ongoing effort to add a logical query optimization layer to Dask DataFrames. We now have the first benchmark results to share that were run against the current DataFrame implementation.
Coiled observability wins: Chunksize
- 19 September 2023
Distributed computing is hard, distributed debugging is even harder. Dask tries to simplify this process as much as possible. Coiled adds additional observability features for your Dask clusters and processes them to help users understand their workflows better.
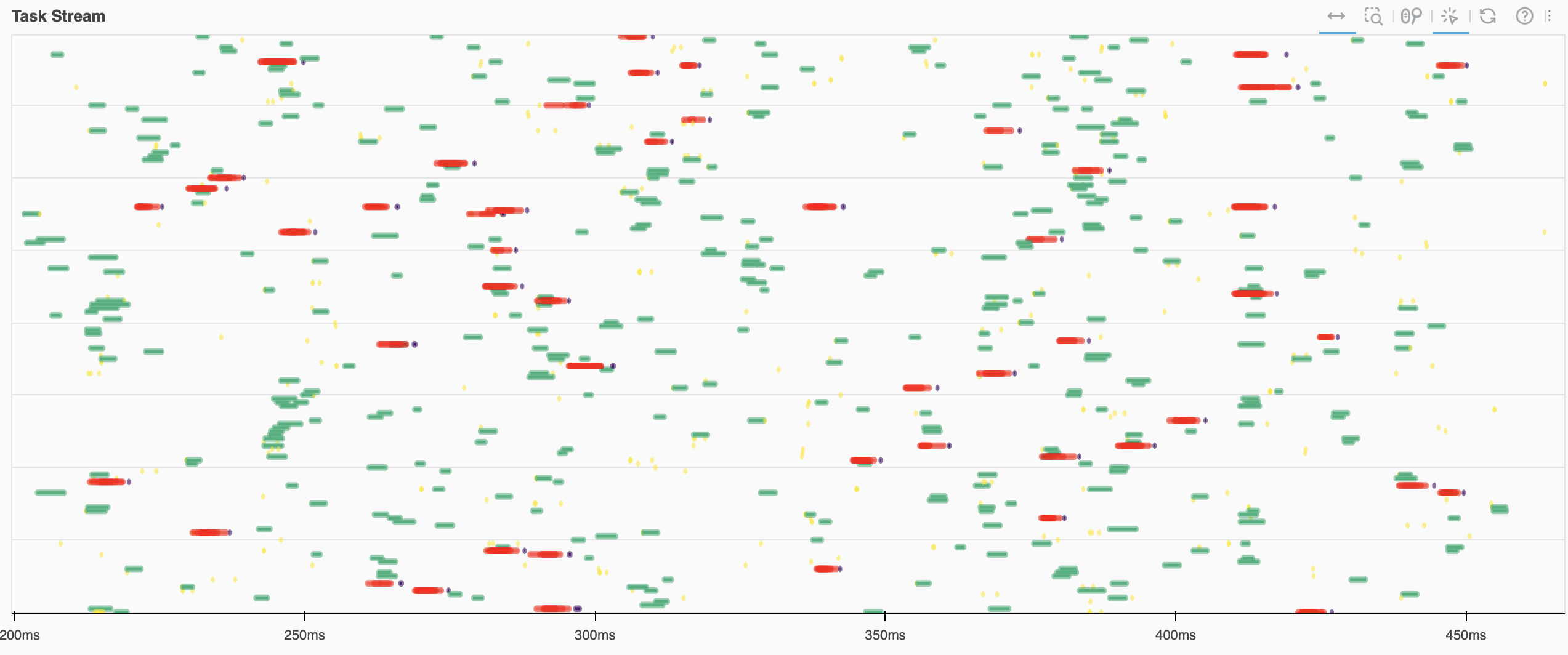
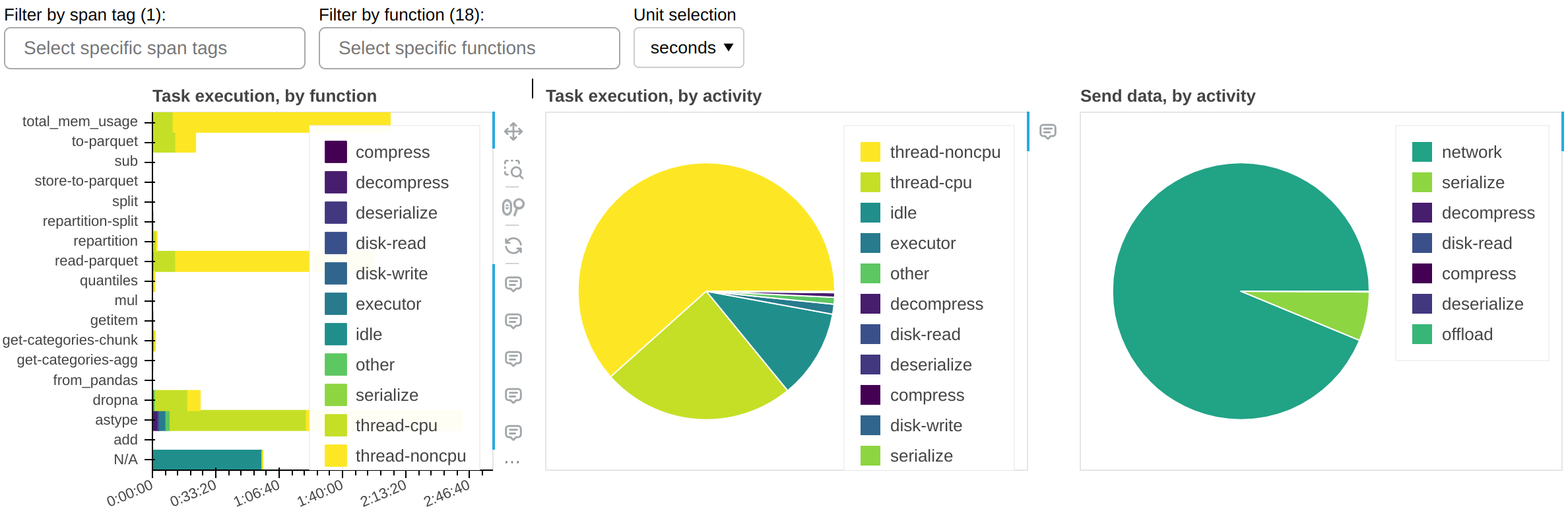
Fine Performance Metrics and Spans
- 23 August 2023
While it’s trivial to measure the end-to-end runtime of a Dask workload, the next logical step - breaking down this time to understand if it could be faster - has historically been a much more arduous task that required a lot of intuition and legwork, for novice and expert users alike. We wanted to change that.
High Level Query Optimization in Dask
- 04 August 2023
Dask DataFrame doesn’t currently optimize your code for you (like Spark or a SQL database would). This means that users waste a lot of computation. Let’s look at a common example which looks ok at first glance, but is actually pretty inefficient.
Dask performance benchmarking put to the test: Fixing a pandas bottleneck
- 23 June 2023
Getting notified of a significant performance regression the day before release sucks, but quickly identifying and resolving it feels great!
Utilizing PyArrow to improve pandas and Dask workflows
- 05 June 2023
Get the most out of PyArrow support in pandas and Dask right now
Distributed printing
- 18 May 2023
Dask makes it easy to print whether you’re running code locally on your laptop, or remotely on a cluster in the cloud.
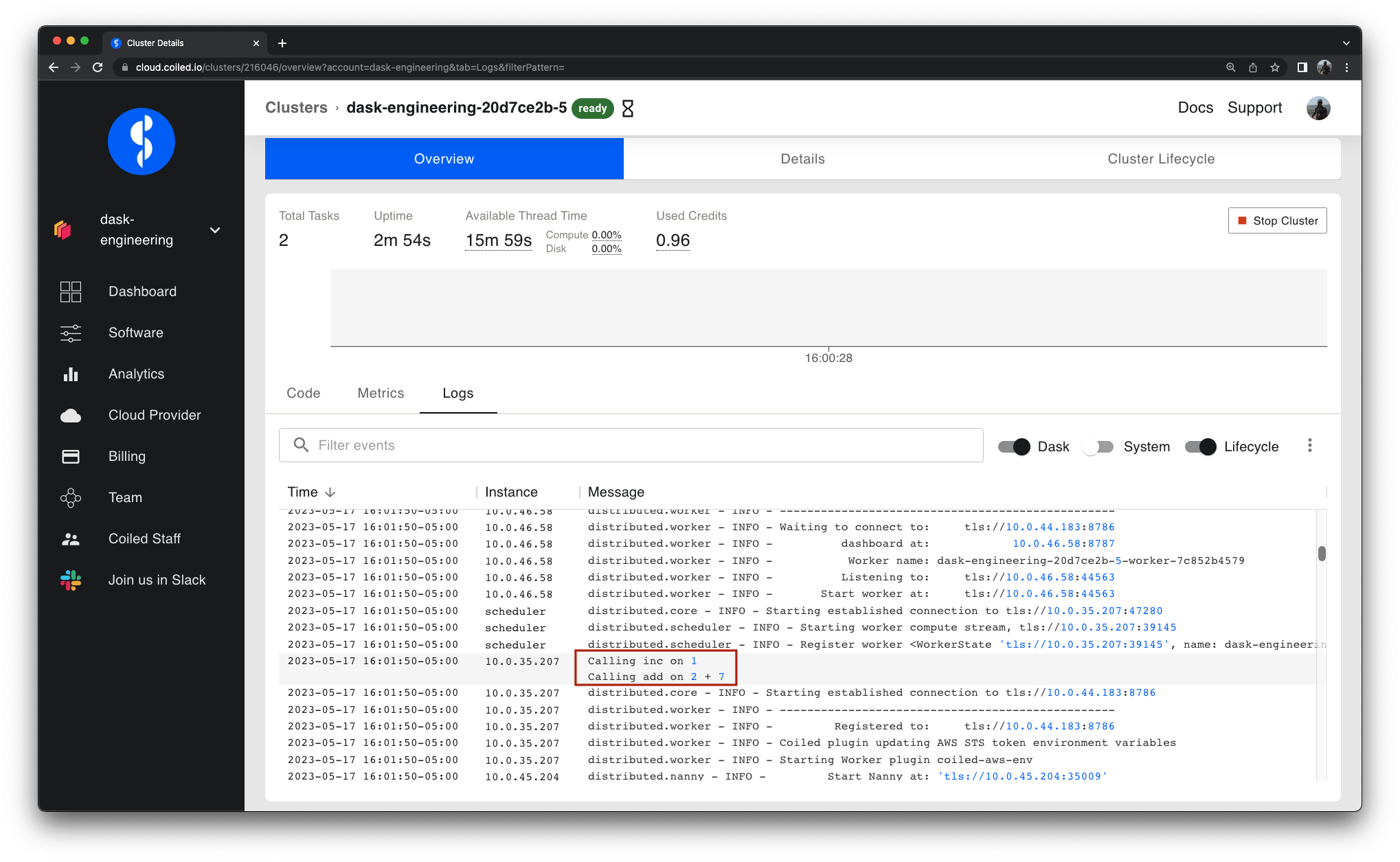
Observability for Distributed Computing with Dask
- 16 May 2023
Debugging is hard. Distributed debugging is hell.
When dealing with unexpected issues in a distributed system, you need to understand what and why it happened, how interactions between individual pieces contributed to the problems, and how to avoid them in the future. In other words, you need observability. This article explains what observability is, how Dask implements it, what pain points remain, and how Coiled helps you overcome these.
Performance testing at Coiled
- 05 May 2023
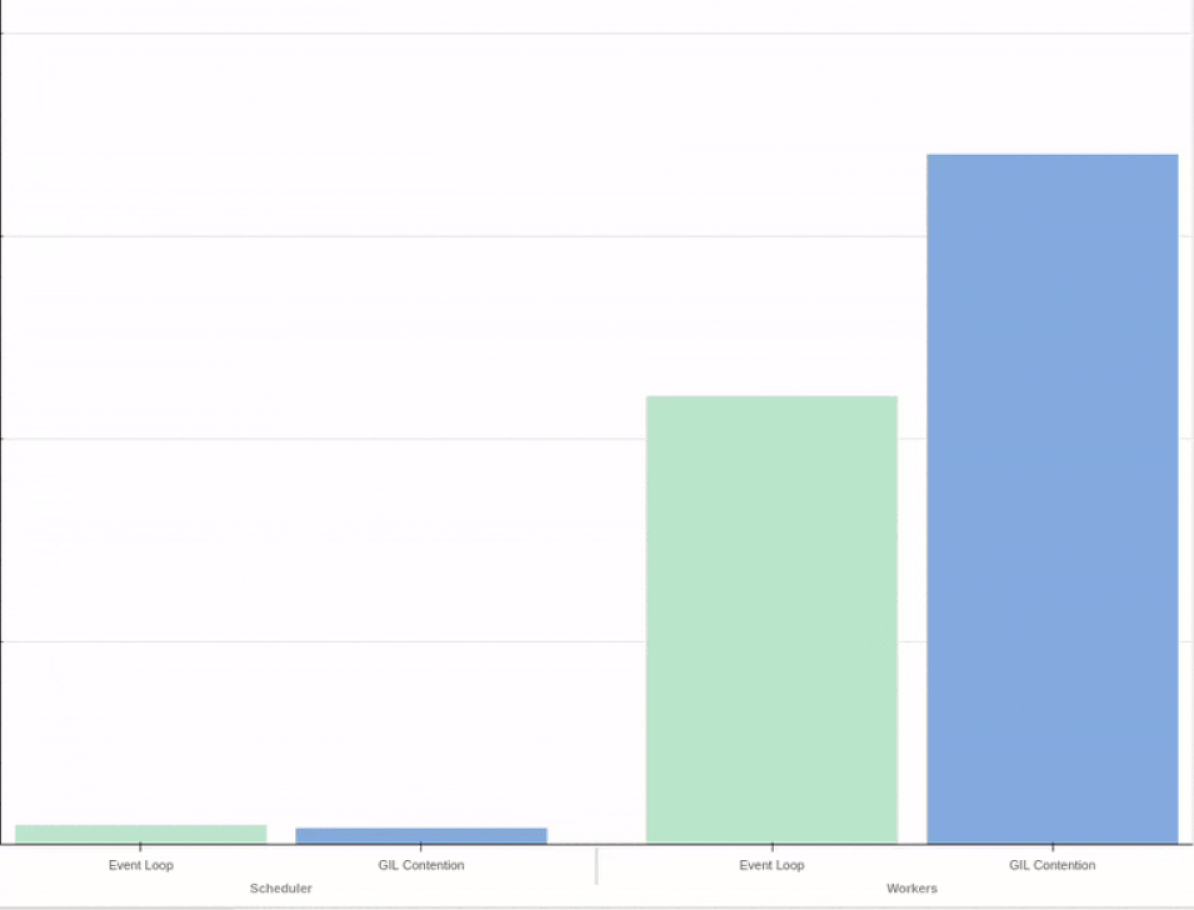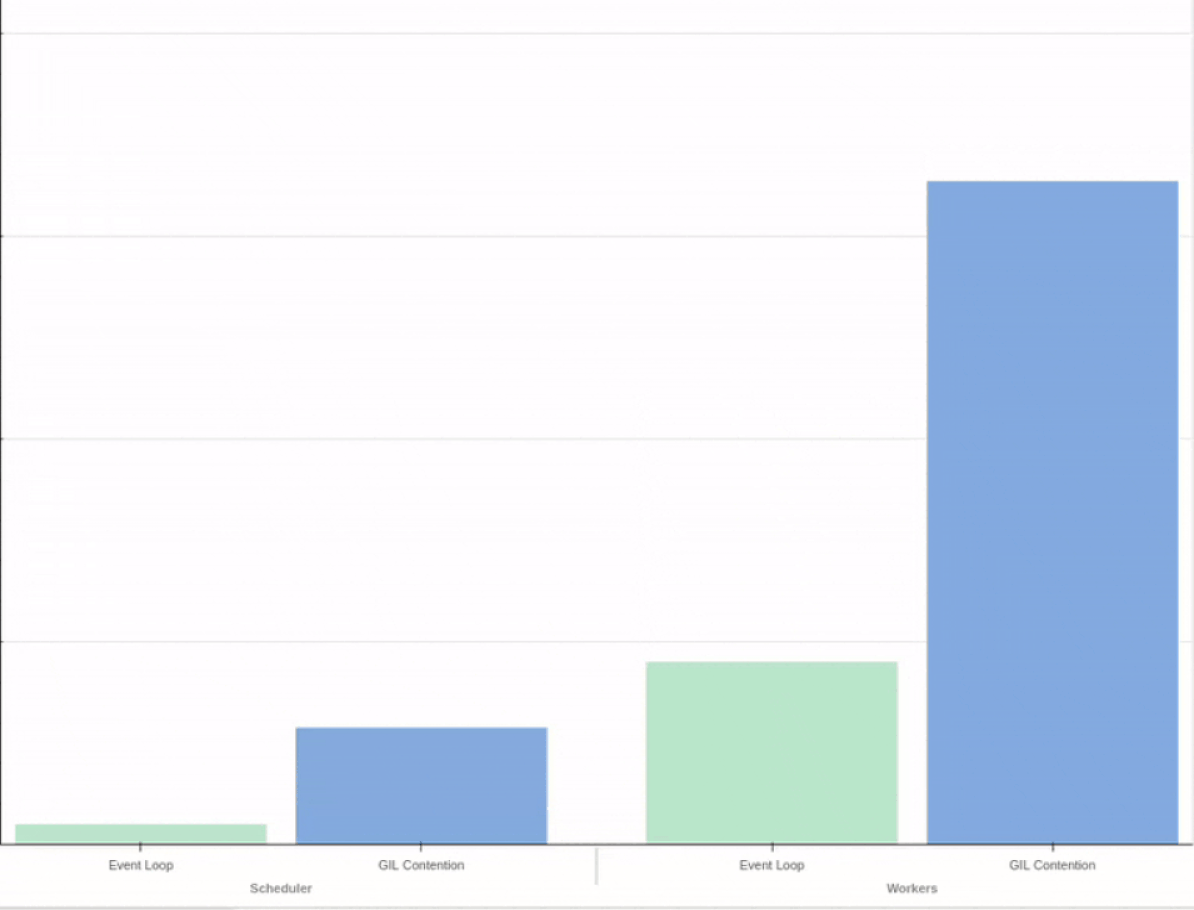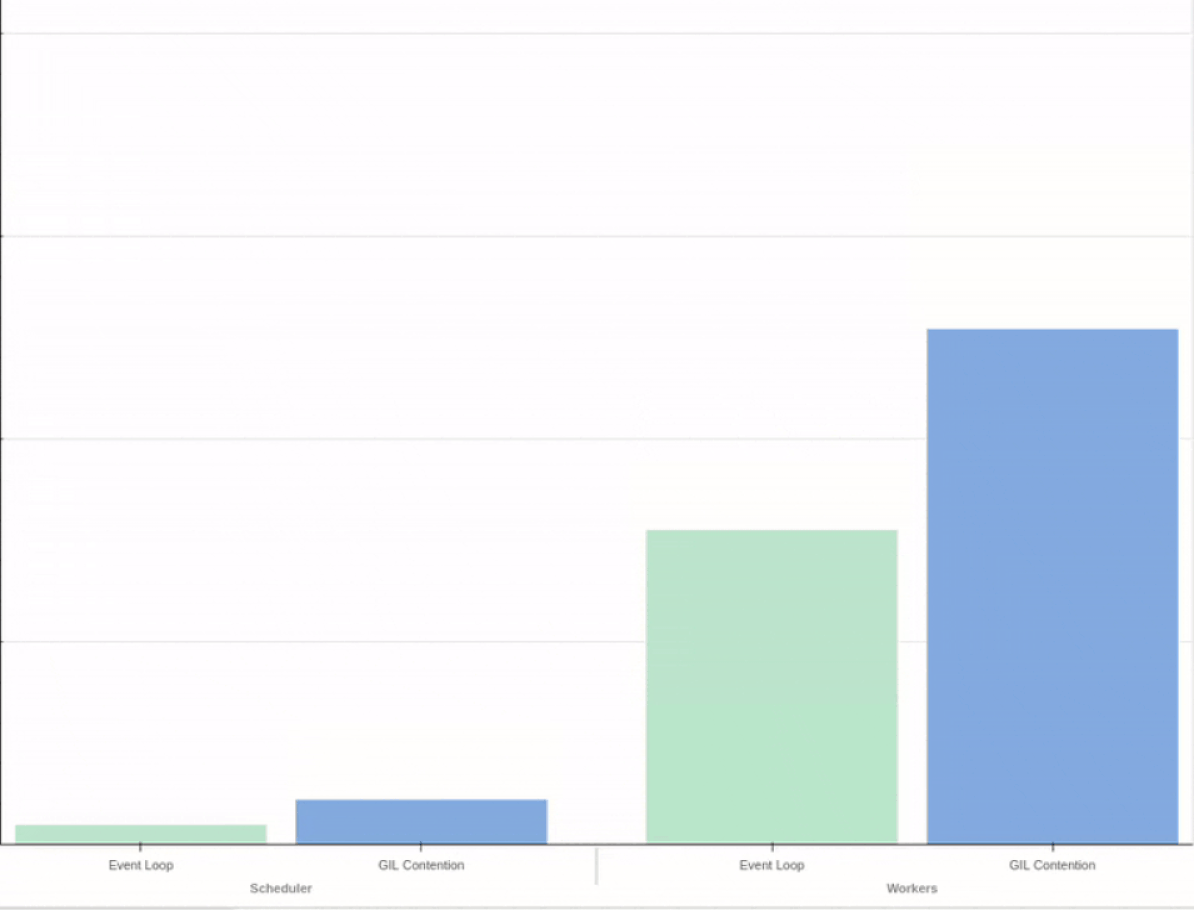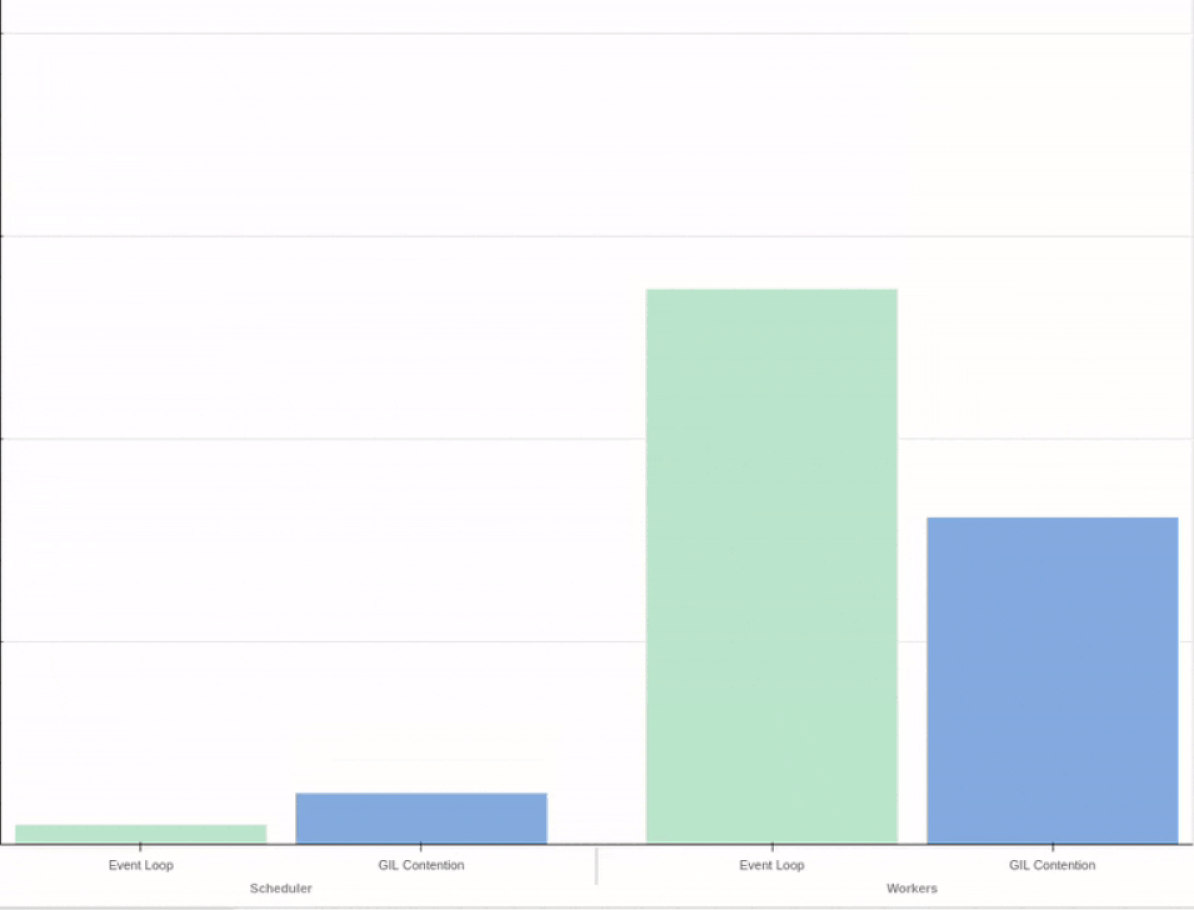
At Coiled we develop Dask and automatically deploy it to large clusters of cloud workers (sometimes 1000+ EC2 instances at once!). In order to avoid surprises when we publish a new release, Dask needs to be covered by a comprehensive battery of tests — both for functionality and performance.
Upstream testing in Dask
- 18 April 2023
Dask has deep integrations with other libraries in the PyData ecosystem like NumPy, pandas, Zarr, PyArrow, and more. Part of providing a good experience for Dask users is making sure that Dask continues to work well with this community of libraries as they push out new releases. This post walks through how Dask maintainers proactively ensure Dask continuously works with its surrounding ecosystem.
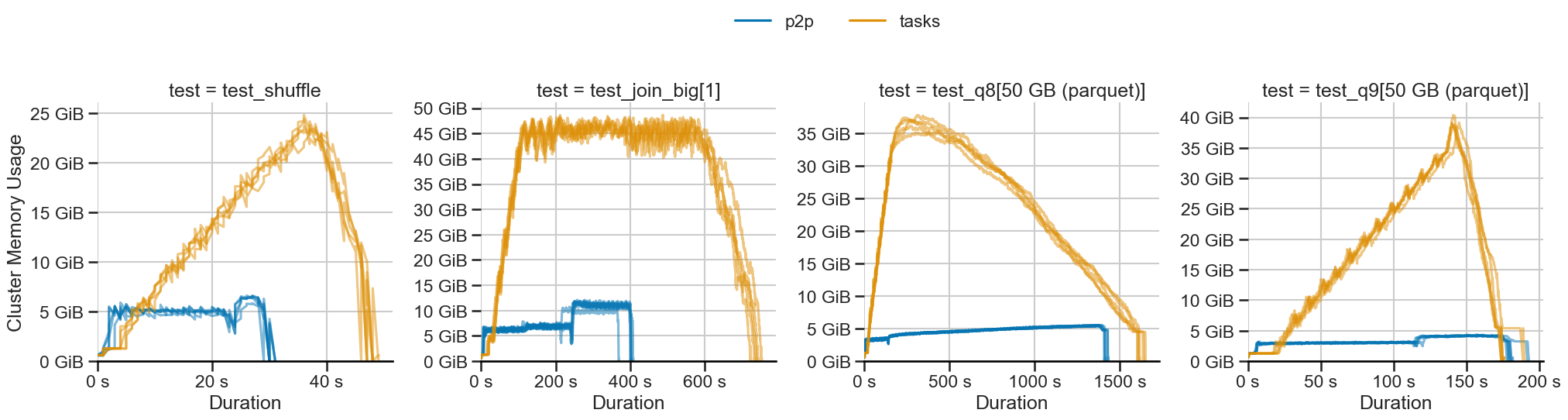
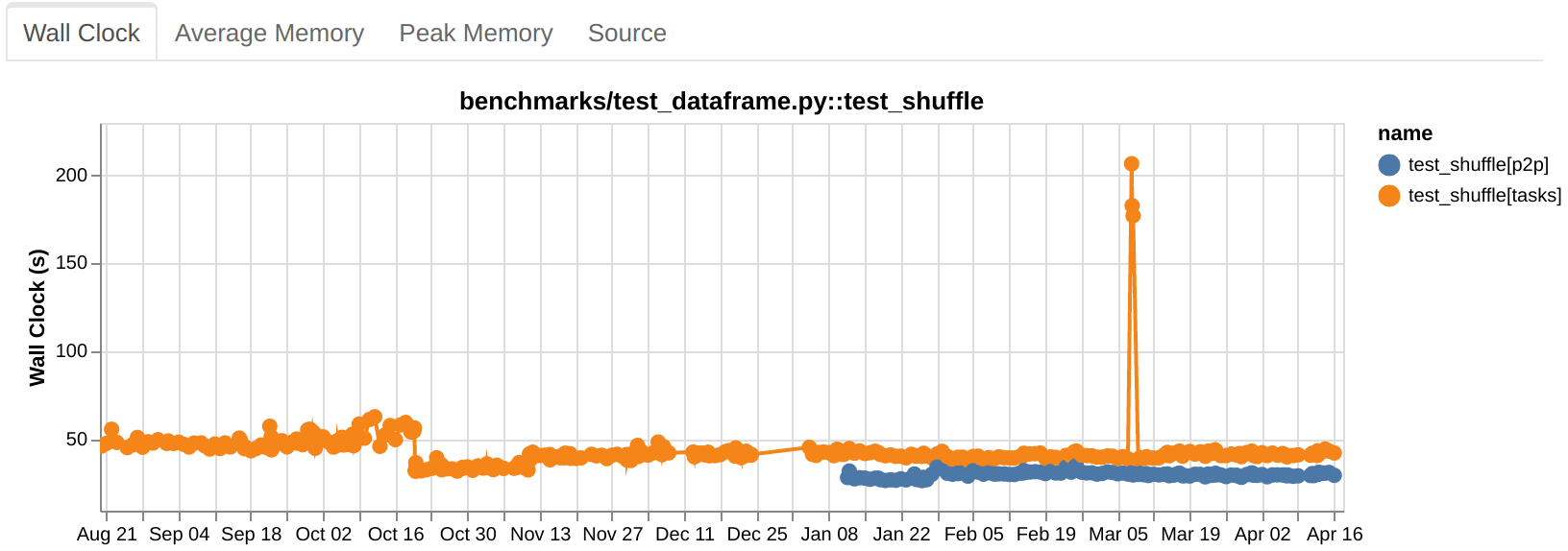
Shuffling large data at constant memory in Dask
- 15 March 2023
With release 2023.2.1, dask.dataframe introduces a new shuffling method called P2P, making sorts, merges, and joins faster and using constant memory.
Benchmarks show impressive improvements: